為下一個模型而寫,別為上一個:Anthropic 三場演講的開發心法

最近 Anthropic 的 Code with Claude 大會釋出了一系列演講,其中有三場小編覺得特別值得連在一起看:Alex Albert 的 The Capability Curve(能力曲線)、Matt 的 The Thinking Lever(思考這根槓桿),還有 Lucas 的 The Expanding Toolkit(不斷擴張的工具箱)。
三位都是 Anthropic 的 research PM(研究端的產品經理),各講各的主題:一個談模型能力怎麼進步、一個談推理時的算力怎麼花、一個談工具生態怎麼長進模型裡。但三場連起來聽完,小編發現它們其實是從不同角度在講同一件事——你該為「下一個」模型寫程式,而不是為「上一個」。這句話正是 Lucas 最後一張投影片的標題:「為下一個模型而寫,別為上一個」(Build for the next model, not the last one),拿來當這三場的總綱剛剛好。
以下幫大家把三場的精華整理在一起。
1. 一年之內,模型變強了多少?
Alex 開場先做了個現場調查:覺得 Claude 讓自己一年內快了 10 倍的請舉手——結果舉手的一大片;5 倍?2 倍?幾乎全場都舉了。這不是場面話,他緊接著丟出一個具體數字:在 SWE-bench Verified 這個衡量「模型能不能自己完成一個軟體合併請求(PR)」的評測上,一年前的 Sonnet 3.7 拿 62 分,今天的 Opus 4.7 拿 87 分。
25 分的跳躍換句話說就是:那些一年前 Sonnet 3.7 會搞砸的困難任務,Opus 4.7 成功的機率是它的三倍以上。
Alex 還準備了一段對照示範:用同一句 prompt 要求模型「複製出 Claude.ai」。Sonnet 4 做出來的是一個黑白通用聊天介面,一送出訊息就報錯,基本上只是個好看的空殼;換成 Opus 4.7,直接就有 Claude 的配色、能正確打 API 拿到回應、會記住舊對話、會在訊息裡行內渲染視覺化圖表,甚至自己實作了深色模式——而且用的程式碼行數還更少。
編按:這場演講的重點不在某個特定模型,而在於「在一個每個月都明顯變強的東西上面開發」這件事本身意味著什麼。這個視角,才是三場演講共同的底色。
2. 進步發生在哪三個地方
Alex 把這一年的能力增長拆成三塊,每一塊都對應到開發者實際會踩到的痛點。
🔹 規劃能力:舊模型常見的壞毛病是「先動手、後思考」。Alex 的比喻很傳神——就像他組 IKEA 家具,直接上手,搞到一團亂才回頭看說明書。Sonnet 3.7 大概就是這樣。新模型則會先花時間想清楚、擬好策略,再動手寫程式。
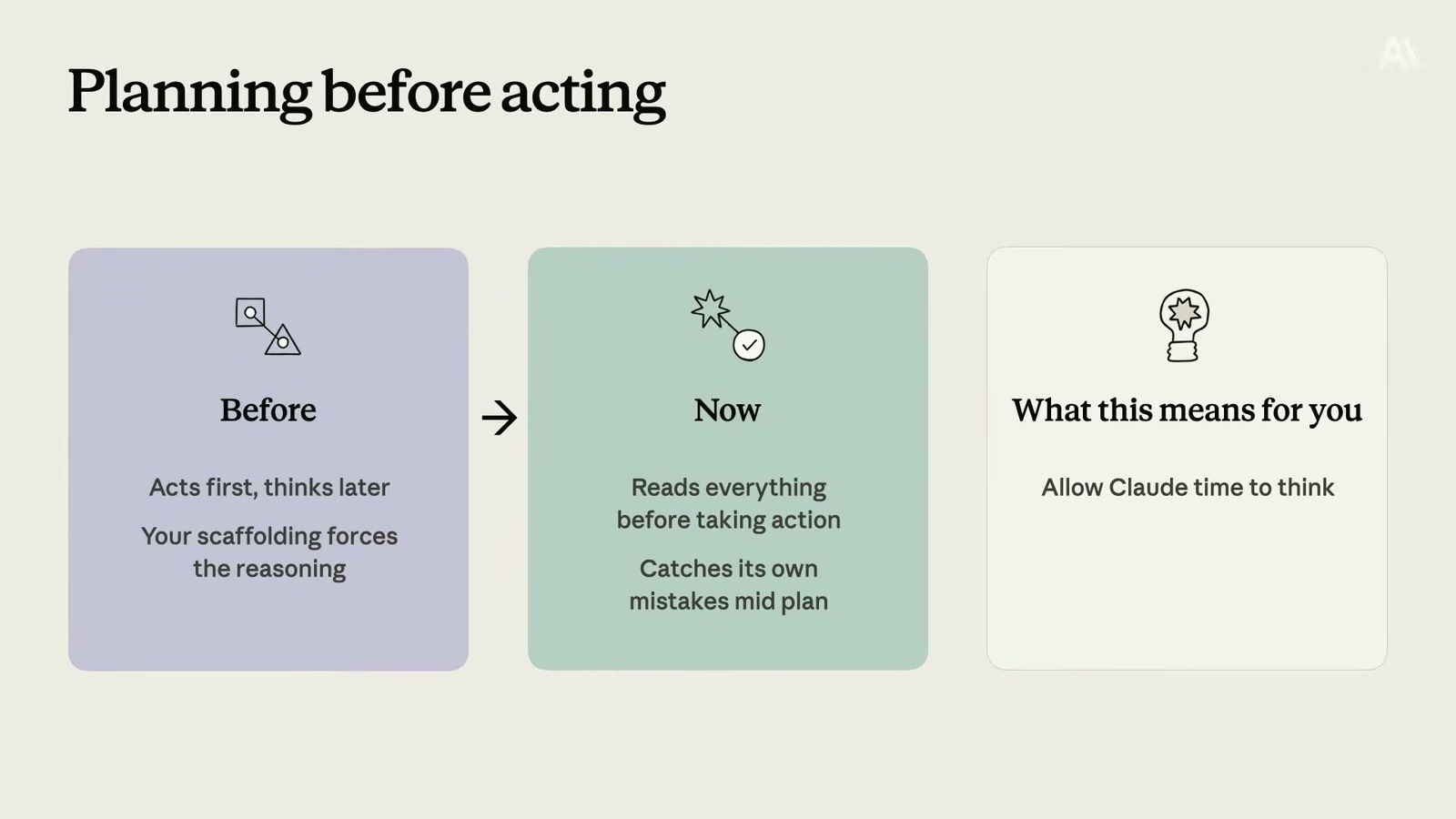
這張投影片講得很白:以前是「先動手再說,而且是你的鷹架在逼它推理」;現在是「動手前先讀完全部,過程中還會抓到自己的錯」。對開發者的意義是——給 Claude 時間思考,別逼它一拿到任務就跳進去寫,那反而會拖累後面的表現。
🔹 錯誤復原:舊模型會陷入所謂的「死亡迴圈」(doom loop)——遇到問題、提一個解法、解法沒用,然後就卡死在那邊一直鬼打牆,直到上下文塞爆,只能整個清掉重來。新模型懂得退回來、換個角度重想、走另一條路。對你的好處是:任務表現更好,又少浪費 token。
🔹 長程注意力:舊模型做久了會「忘記劇情」,你寫在系統提示(system prompt)裡的指示,愈到後面愈不被理會。新模型能在數十萬甚至上百萬 token 的跨度裡維持一致性。
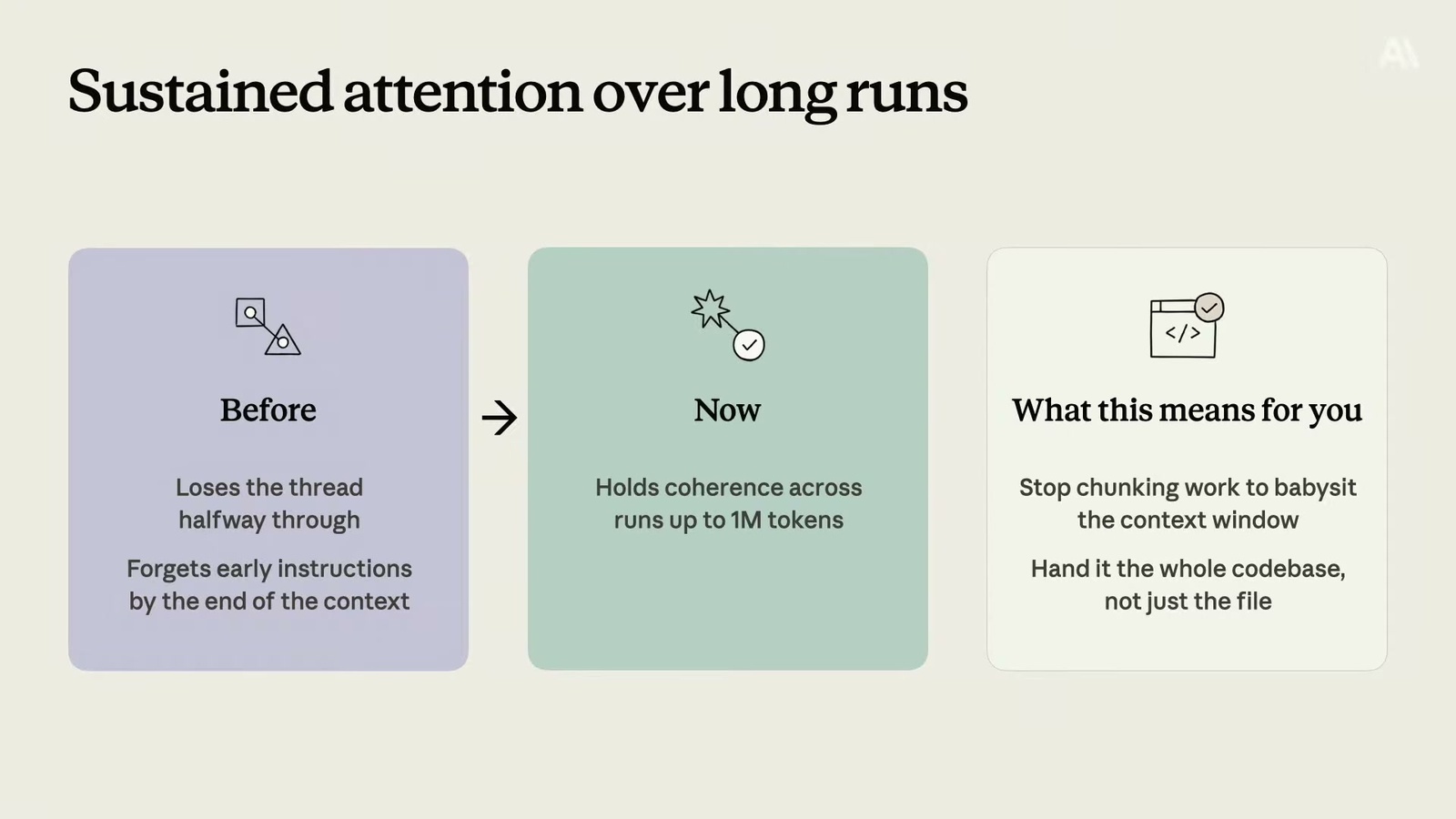
這代表你不用再像保姆一樣盯著上下文視窗,也不用把工作硬切成小塊餵給它——可以直接把整個程式碼庫交給它,信任它自己跑長任務。
把這三點加起來——更好的規劃、更少的錯誤、跑得更久的 agent——複利效應就是端到端任務表現的明顯提升。Alex 也舉了客戶的例子:Vercel 發現 Opus 4.7 會在寫下任何一行程式之前,先替系統程式碼寫好「證明」;Shopify 則看到模型一邊寫、一邊回頭迭代修正自己的輸出。
3. 想看到同樣的進步?先從你的 evals 開始
那開發者要怎麼在自己的應用裡吃到這些紅利?Alex 的第一個建議有點反直覺:不是從你的應用下手,而是從你的 evals(評測)下手。
「能被量測的東西,才能被改進。」重點有兩個:你得有 evals,而且這些 evals 要貼近你產品真正的任務分布。聽起來像廢話,但他說這正是很多團隊走偏的地方——明明做的是 coding agent,卻拿學術界的程式評測去測,而不是用接近自家使用者真實流量的資料。
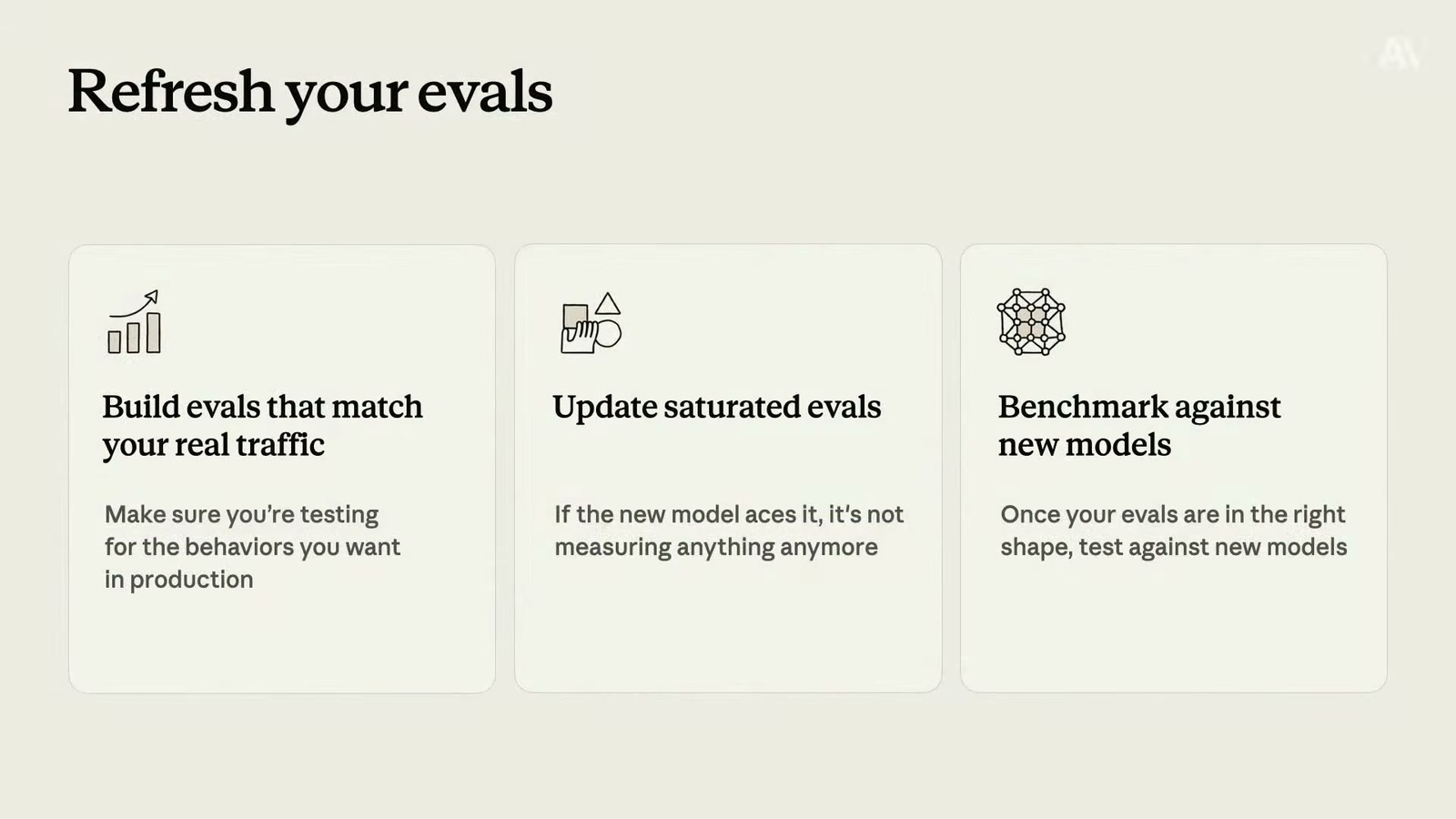
接著還要做兩件事。一是確保 evals 沒有飽和:模型愈來愈聰明,evals 也得跟著愈做愈難,不然就抽不出新的訊號了——如果新模型輕鬆滿分,那這份 evals 已經量不出東西了。二是拿新出的前沿模型來測。Alex 說了一句小編很有感的話:有時候對你應用最好的優化,就只是換上最新的模型而已。所以每次有新模型,花點時間認真測,很值得。
4. 回頭看你的鷹架和 prompt——記得做減法
第二個建議:重新檢視你的鷹架(scaffolding)。Alex 對鷹架的定義是「圍繞在模型外面、把它導向目標的那些程式碼、prompt、skill 和工具設定」。
關鍵心法是做減法。新模型可能不再需要你以前搭的那些東西。也許以前要拆成多步驟的工作流,現在一輪對話就能搞定。「常常,你是靠『拿掉』而不是『加上』東西來提升表現的。」
prompt 也一樣。Prompt 會一代一代累積,久了就變成一坨醜陋的規則大雜燴,你自己都搞不清楚當初為什麼加某一條、它現在到底還有沒有用。每換一個新模型,就回頭砍掉那些可能已經用不到的指令——既救表現,又省 token。
5. 給模型發揮的空間

第三個建議,Alex 用一張投影片收斂成三點:
1️⃣ 讓 Claude 自己決定何時思考:用適應性思考(adaptive thinking),搭配 effort(努力程度)參數去調它思考和行動所花的 token。(這正好接到第二場演講的主題,等下細講。)
2️⃣ 用受控的方式,給 agent 更多工具權限:聽到這句有些人會緊張,但 Alex 強調他不是要你放任它亂搞。他舉 Claude Code 的 auto mode 為例:它會跑分類器去判斷 Claude 提出的每個工具呼叫到底需不需要人類明確批准,讓 Claude 可以在背景跑更久、更自主,不必一直停下來等人點頭。
3️⃣ 替 agent 把迴圈閉合:設計你的系統,讓 Claude 能檢查自己的輸出、然後迭代。比方說做前端的 coding agent,給它一個操作電腦的工具,讓它自己點開網站、實測它寫出來的功能對不對。
6. 第二根槓桿:在推理時花算力
第一場談的是「模型本身變強」,Matt 的第二場則談另一條變強的路徑:test-time compute,也就是推理時算力(inference-time compute),這就是大家熟知的「推理模型」背後那回事。
就像我們可以在訓練時用更大的模型、更多資料、更長時間來擴展算力,我們也可以在推理時讓模型「多花點時間」解一個問題。Matt 給了兩張對照圖:一張是從 Haiku 到 Sonnet 到 Opus,模型愈大,程式評測分數愈高;另一張是同一個 Opus,單純讓它在一個問題上花更多時間,分數也跟著往上爬。而且這不只適用於軟體工程,agentic 搜尋、操作電腦、博士級的學術推理,通通吃這一套。
7. 同一個模型,從 50 秒到 593 秒
光看圖表不夠直觀,Matt 用一個有趣的示範把這件事具象化:他要 Opus 4.7 寫一個「車流在單行道紅綠燈前的真實模擬」,然後分三種努力程度跑。
- 低 effort:約 50 秒、4,600 個輸出 token。車子會跑、會停紅燈,功能算過關,但畫面陽春,而且 Claude 把紅綠燈擺在馬路正中央(設計品味堪憂)。
- 高 effort:時間和 token 都加倍,結果明顯更好——有不同車種,紅綠燈也乖乖移到路邊,甚至實作了它自稱的「智慧駕駛模型」,每台車會根據周圍車況反應。
- 最高 effort:時間和 token 都是低 effort 的 10 倍(就是封面那張,593.1 秒、52,893 個 token),畫面、燈號、駕駛行為全都最逼真。
這個示範的重點是:同一個模型,光是讓它多花時間,結果就會更好。Matt 說隨著推理時算力繼續往上推,Claude 未來解一個問題花的時間不會只是幾秒、幾分鐘,而可能是幾天、幾週、甚至幾個月,拿來啃人類最難的問題。
8. Claude 花的三種 token
Matt 把「推理時花算力」拆成三種 token,這個分類小編覺得很實用:
- 思考 token:Claude 的內心獨白,一步步推理、權衡選項、打草稿的空間。
- 工具呼叫 token:Claude 跟外部世界打交道的方式,搜尋、讀寫檔案都算。
- 文字 token:Claude 跟「你」溝通的方式,回報進度、最後做總結,或單純回答你的問題。
這三種對使用者都有實際成本——你付的 token 錢,還有等待的時間。Claude 花愈多 token,你就等愈久。所以 Anthropic 認為,給使用者「影響或限制 Claude 怎麼花 token」的能力很重要。
方法有兩種。一是 effort 旋鈕:告訴 Claude 你希望它怎麼在時間、成本、品質之間取捨。二是 預算上限:他們最近推出的「任務預算」(Task Budgets)讓你設一個上限,例如「幫我做這個功能,但花超過 10 萬 token 就先停下來跟我確認」。預算可以是 token 數、時間或金額——當 Claude 動不動就要跑上好幾天的時候,這種「先講好做多久就回報」的機制會愈來愈重要。
9. 從固定順序到「適應性思考」
那給了努力程度和預算之後,Claude 內部到底怎麼分配這三種 token?Matt 講了一段演進史:
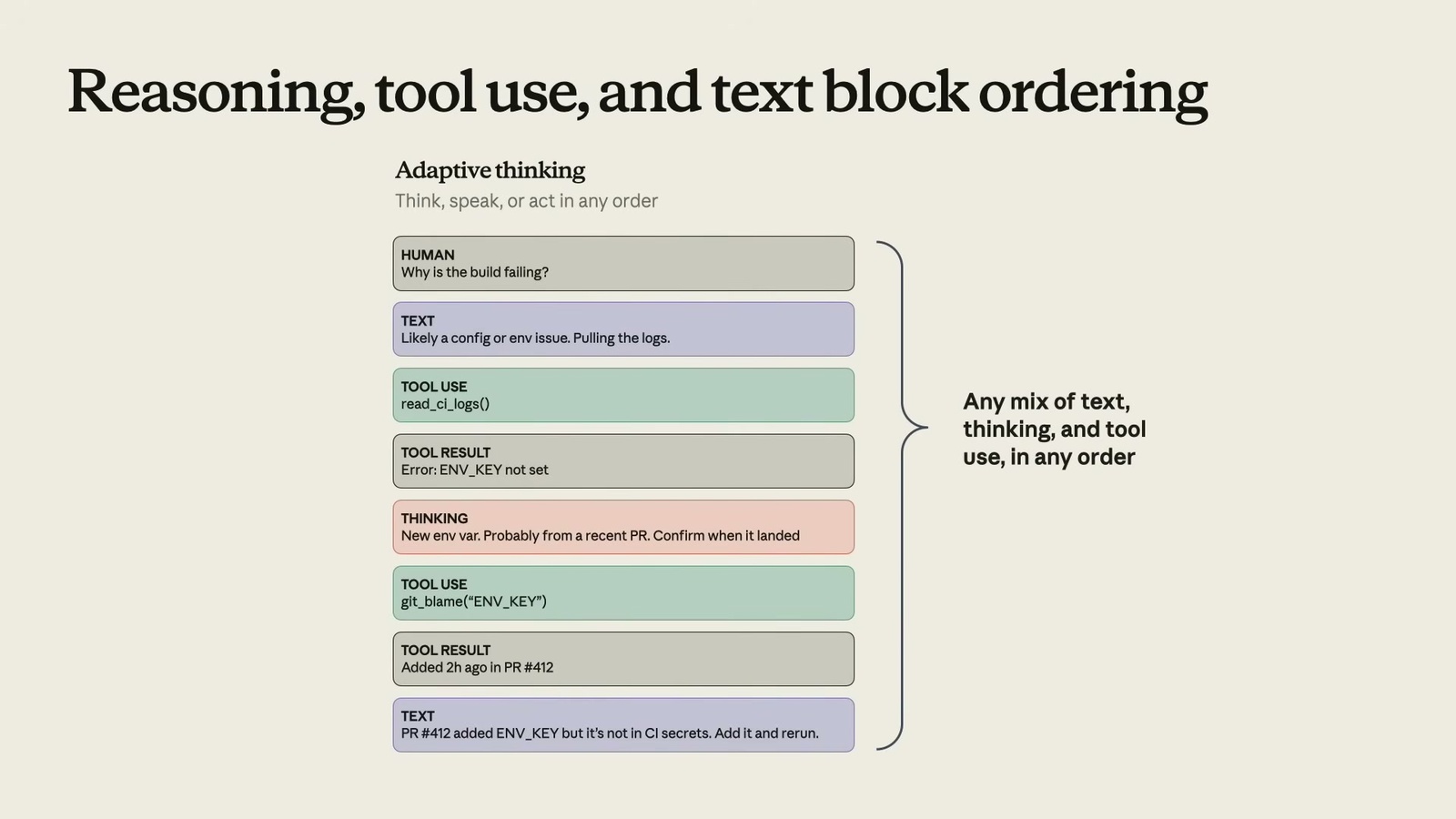
最早的推理模型是固定順序:先思考、再呼叫工具、最後輸出文字。後來有了交錯思考(interleaved thinking),Claude 可以在工具呼叫「之間」插入思考——呼叫工具、拿到結果、想一下、再決定下一步。最近則進化到適應性思考(adaptive thinking):Claude 完全自由,想在哪一步思考都行,順序、長度都不設限,遇到簡單的問題甚至可以完全不思考。如上圖,它可以是「文字 → 工具 → 工具結果 → 思考 → 工具 → ……」任意組合。
Matt 特別澄清兩個誤解:適應性思考不是模型路由器(它不會把問題分類後丟給「思考版」或「非思考版」模型),也不是自動開關思考的那種開關。它的本質,是把「你必須在回應一開始至少花一個思考 token」改成「你想在任何步驟思考都可以」。Anthropic 從 Opus 4.6 開始,所有評測都跑在適應性思考上,因為它在維持(甚至超越)交錯思考表現的同時,還能給更好的使用體驗。
10. 別再把 thinking 開關當「努力程度」在用
這段小編覺得是整場最關鍵的觀念。過去大家習慣把 thinking 開關當成「努力程度」在調——想讓 Claude 認真點,就去 Claude.ai 或 Claude Code 把 thinking 打開。直覺上很合理,但 Matt 說這是個很糟的替代指標。
因為打開或關閉 thinking,其實是在開關模型的一個「核心能力」,你限制的是它「能怎麼工作」,而不是「你要它多努力」。effort 旋鈕才是「多花 token 換更好答案」這個意思的正確表達——它會同時調動思考、工具使用和輸出文字,而不是只切掉其中一個。
Matt 的類比很到位:就像我們用工具時,不會叫 Claude「永遠都要搜尋」或「永遠別搜尋」,而是讓它自己判斷何時該搜;同樣地,我們跟同事共事,也不會叫他「把內心獨白打開或關掉」,我們只會問他「這件事要多拚」,然後讓他自己決定要想多深、做哪些動作。
11. effort 等級怎麼選?還有低 effort 帶來的驚喜
有 evals 的話,Matt 建議畫一條「努力曲線」:X 軸放 token / 時間 / 成本,Y 軸放表現,就能看清楚每一級的取捨。提高努力程度通常能改善大多數「吃智力」的任務,但會出現邊際遞減——你可能會發現 extra high 跟 max 表現差不多,但 token 差很多,那選 extra high 就夠了。
沒有 evals 的話,Matt 也給了幾條經驗法則:
- Max(最高):最難的任務才用,小心邊際遞減,別預設它一定是表現天花板或最划算的選擇。
- Extra high(極高):Opus 4.7 新增的等級,也是它在 Claude Code 和 Claude.ai 的預設值。大多數 coding 和 agentic 用途的最佳設定,智力拉好拉滿又不會太過頭。
- High(高):想在 token 和智力之間取平衡的好起點。
- Medium(中):成本敏感、願意稍微犧牲一點智力換速度時用。
- Low(低):留給範圍小、對延遲敏感的任務。
不過低 effort 也給過 Matt 驚喜。他最愛的評測之一是「Claude Plays Pokemon」(讓 Claude 玩寶可夢紅版)。用低 effort 跑起來,Claude 居然把遊戲當成「速通」在玩——跳過訓練家對戰省時間、囤好補品就地補血而不跑寶可夢中心、狂用「除蟲噴霧」減少洞窟裡的雜魚遭遇。小編覺得這例子很妙:我們常把低 effort 跟「比較笨」劃上等號,但要想出「怎麼把 token 花到最省、最快通關」其實需要相當的智力。Claude 把「低 effort」理解成「用最聰明的方式偷懶」,反而很有梗。Matt 也提醒,低 effort 時 Claude 一心想省 token,偶爾會抄一些你沒預期到的捷徑,所以除了看 evals,平時也該多讀讀它的對話紀錄,搞清楚它在某個努力程度下到底怎麼回應。
12. 小模型 vs 大模型開低 effort
既然推理時算力和訓練時算力都能換智力,那到底何時該用小模型、何時該用大模型開低 effort?Matt 的判斷準則:
- 大模型開低 effort:適合「吃智力但要快」的場景。以那個車流模擬為例,Opus 4.7 開低 effort 花的 token 跟 Haiku 4.5 開最高 effort 差不多、時間也只多一點點,但結果好很多。
- 小模型:適合「不太吃智力、但要省錢」的場景,尤其是要大量處理的簡單任務——分類、資訊抽取、基本摘要。另外,如果你的應用很在意「第一個 token 多快吐出來」,小模型天生就更快。
Matt 的口訣很好記:要讓「第一個 token」快,用小模型;要讓「最後一個 token」快,用大模型開低 effort。
收尾他給了三個帶得走的重點:一,能開思考就開思考,給 Claude 推理的空間;想調思考多寡,用努力程度或預算,別用開關。二,有 evals 就用 evals,畫曲線、測不同努力程度和模型。三,什麼都不想搞、又在做 coding 的話,直接選 extra high 就對了。北極星目標是:你設好品質門檻和預算,剩下的交給 Claude,它自己把算力分配到剛剛好。
13. 第三場:去年要自己搭的鷹架,今年內建進模型了
Lucas 的第三場把視角從「模型」拉到「模型周邊的生態」。他一句話點題:去年你得自己搭的鷹架,今年隨模型一起出貨了。所以別再把模型想成一個「輸入進去、輸出出來」的 LLM 盒子,而要把它想成一組會持續擴張、不斷增強自身能力的工具箱。
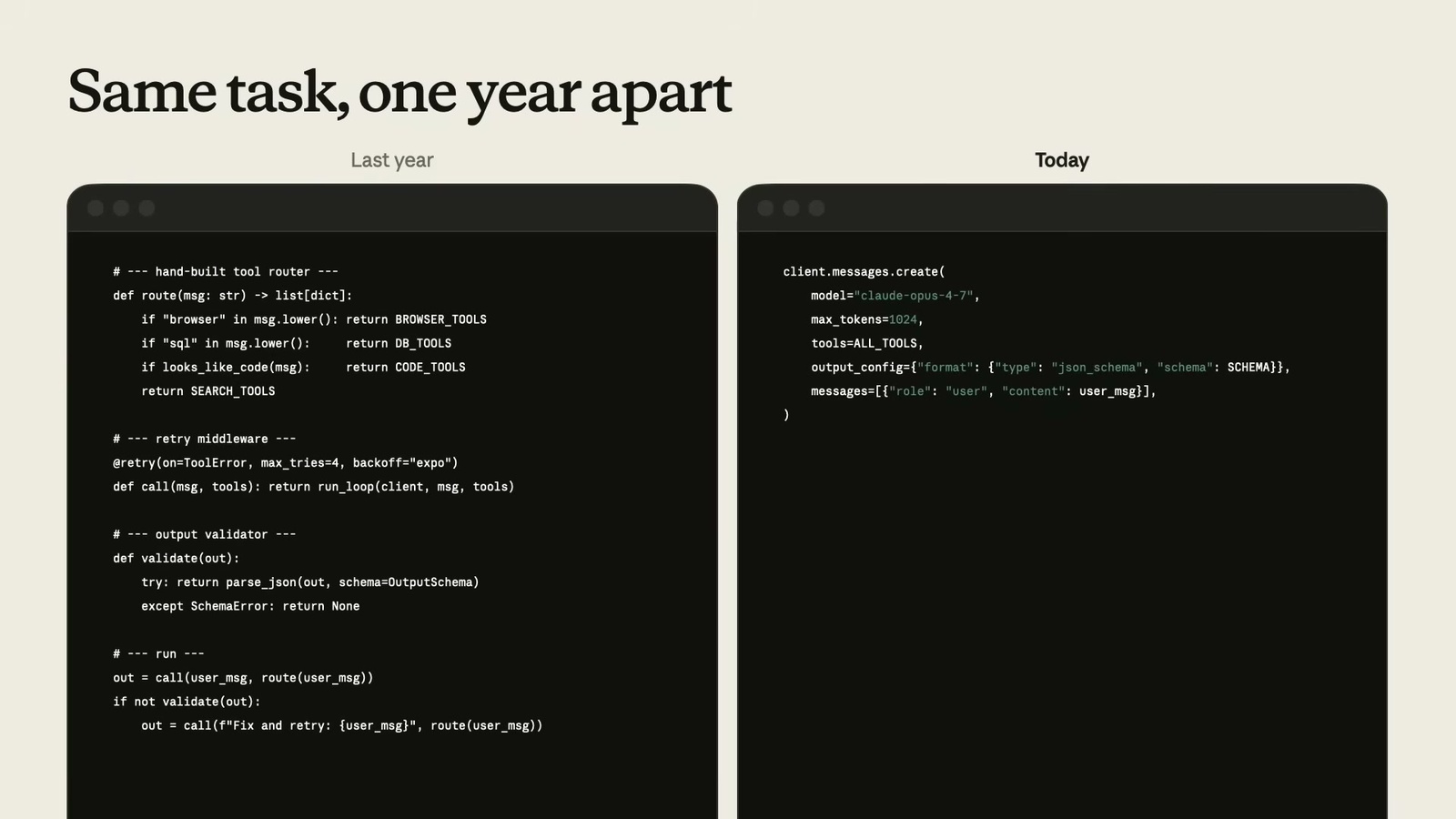
整場演講是一連串「去年 vs 今天」的對照,上面這張就是最好的縮影。左邊是去年:你得手寫一個挑工具的路由器(看到 SQL 就給資料庫工具)、外面包一層重試機制、再加一個輸出驗證器、最後串成一個跑迴圈——洋洋灑灑一大段。右邊是今天:就是一次 client.messages.create() 呼叫,把全部工具丟給它(tools=ALL_TOOLS)、順手指定輸出格式就好。Lucas 說重點不是這些工作「消失」了,而是它「搬家」了——搬進模型本身,你不必再自己扛。
14. 四個被模型吸收掉的能力
🔧 工具使用:以前你不敢把全部工具丟給模型(會吃爆上下文),只好寫一個路由器——用字串比對、各種啟發式規則,例如「模型提到 SQL 就給它資料庫工具」,外面再包一層重試。Lucas 直言這種路由器「本質上就是用 if 條件寫死的、對使用者意圖的猜測」,又脆、又是你加新工具時第一個壞掉的東西。現在模型夠聰明、選工具的準確率夠高,自己寫路由器和預先過濾反而常常幫倒忙;工具報錯時,你也可以信任 Claude 自己看到錯誤、復原、重試。小技巧:給工具時,大多數人只給「輸入」的格式,但你也可以把「輸出」的格式描述給 Claude——例如告訴它這個搜尋工具會回傳 id、標題、摘要、分數,那它想對結果排序時,就知道有分數可用,省下一次往返。玩 Claude Code 的人還可以在工具呼叫的前後掛 hook,程式化地做事(擋掉特定呼叫、或事後記錄輸出)。
🗂️ 上下文管理:以前長時間跑的 agent 得自己搭記憶系統——把文件切塊(chunking)、做 RAG、每隔幾輪就叫另一個模型來摘要,還要手動搬「快取斷點」省錢。現在呢?一百萬 token 的上下文長度搭配統一定價,先解掉大半壓力;再加上伺服器端的壓縮(compaction)和上下文編輯(context editing),剩下的就只是幾行設定,逼近「無限上下文」的體感。小技巧:每隔幾輪就清掉過時的工具結果(截圖、搜尋結果、讀檔內容這類),但保留 Claude 在對話裡記下的「決策」,就能即時省下大量 token。玩 Claude Code 的人可以打 /context,看到一張彩色格狀圖,直觀感受訊息、工具結果、系統提示、MCP 定義各占掉多少上下文。
💻 程式碼執行:以前「寫 → 跑 → 修」這個迴圈是開發者的活——找虛擬機(VM)供應商、開沙箱、把模型產的程式碼丟上去跑、解析錯誤訊息、再餵回模型,反覆直到成功。現在有了「程式碼執行」工具,自動在伺服器端給 Claude 一個沙箱,整個迴圈在「一次 API 往返內」就跑完,不用在 Claude 和你的虛擬機之間來回。Lucas 給的心智模型很好懂:這就像給 Claude 一台自己的電腦當「草稿紙」,它可以裝套件、跑資料分析、做運算,完全不弄髒你本機的檔案系統;當它需要碰只存在你本機的東西(你的程式碼倉庫、Python 環境)時,才回到真正的本機 bash,而且它分得清楚什麼時候該用哪一邊。玩 Claude Code 的人可以用 /schedule 排定由 cron 觸發的自主執行。
🖱️ 操作電腦:以前要讓 Claude 操作你的筆電,得寫一堆「影像膠水」——1080p 截圖先縮小到模型的像素上限、記住縮放比例、模型選好點擊位置後再把座標放大回原解析度,外面還要包重試和驗證。Opus 4.7 現在能直接吃原生解析度的截圖,在 1440p 以內回傳一比一的像素座標,縮放數學整個消失,你把圖送出去就好,信任它會點對地方。這個能力進步神速:招牌評測 OSworld(衡量模型在專業與消費級軟體上完成複雜任務的能力),不到 12 個月前 Claude 還在 50 分以下,連一半任務都做不完;Opus 4.7 報出 78 分,馬上要破 80。小技巧:1440p 以內建議多試不同解析度和影像格式(JPEG / PNG / WebP 的壓縮特性都不一樣);至於 4K 這種超高解析度,還是建議自己先縮小。玩 Claude Code 的人裝了 Claude in Chrome(到 claude.ai/chrome 取得),就能讓 Claude Code 直接開瀏覽器測試,連本機的開發環境也行。
Lucas 還放了一段示範:一個有錯誤的專案管理看板,Claude 自己用 Chrome 打開、重現「按了新增卻沒長出卡片」的錯誤、邊測邊改程式碼修好;接著測試拖拉功能時把卡片誤拉到錯的欄位,辨識出這也是錯誤、即時寫修正、再從頭重測一遍。小編覺得這個迴圈很關鍵——因為今天大多數軟體是給「人」用的,就得用「像人」的方式去測。讓 Claude 能在開發過程中操作瀏覽器,它才能自己閉合「寫出給人用的軟體 → 自己抓錯修好」這個迴圈,不必開發者手把手帶它找問題。
15. 一條判斷程式碼價值的鐵則
Lucas 結尾給了一條小編認為三場演講裡最該抄下來的規則:
任何你寫來「補償模型不可靠」的程式碼,半衰期只有幾個月。那種活,留給 Anthropic 就好。

這張收尾投影片把整件事講得乾淨俐落。左邊大標就是「為下一個模型而寫,別為上一個」,副標寫著「每一個軟體都正在長出一道給 agent 的前門,你的優勢就在你那道前門背後」。右邊兩張卡片是對照組:「補償模型(重試、路由器、規劃器、驗證迴圈)→ 半衰期以月計」對上「連接你的世界(工具、上下文、權限驗證、資料)→ 會複利成長」。
重試邏輯、路由器、規劃器、驗證迴圈……這些都正在、也將持續被吸收進模型。反過來,那種「把模型接到你世界」的程式碼,價值會複利成長——你的自訂工具、你的資料、你的權限驗證、你獨有的脈絡。一句話收得很漂亮:「模型無法吸收它看不到的東西。」所以把這些餵給它,遠比替它補短處有價值。
Lucas 進一步預言:不久的將來,每一個 agent、每一個軟體,都會長出一道「給 agent 的前門」。於是,有趣的工作不再是「把模型弄得更可靠」,而是「在你那道前門背後,放上別人放不了的東西」。
16. 三場連起來看:為下一個模型而寫
把三場拼在一起,訊息其實高度一致,只是從三個角度切入同一個建議——為下一個模型開發,別為上一個。
- 能力曲線告訴你:進步會複利,所以每出一個新模型,就拿 evals 重測一次,並且勇於對鷹架做減法。
- 思考槓桿告訴你:別再用開關去掐模型的核心能力,改成用努力程度和預算去表達「你要它多拚」,然後讓模型自己分配算力。
- 擴張的工具箱告訴你:別再自己扛「讓模型可靠」這件事,把力氣投在「把模型接到你獨有的世界」上。
貫穿三場的那個不變量,就是 evals——它既是你判斷該不該換模型的依據,也是你決定努力程度的工具,更是你驗證「拿掉鷹架之後表現有沒有變好」的那把尺。模型會吃掉所有通用的、會過時的東西;而你真正該擁有的,是那些專屬於你、模型再怎麼進步也複製不走的部分。
下次你又想替模型多寫一層保護網之前,也許可以先問自己一句:這段程式碼,是在補上一個模型的短處,還是在替下一個模型鋪路?