軟體工程佔了 AI Agent 近 50% 的 Agentic API 呼叫 — 從數據看 Agent 自主性的現實與未來
看到 Anthropic 發了一篇研究 Measuring AI agent autonomy in practice,分析了數百萬筆人類與 AI Agent 的互動數據,涵蓋 Claude Code 和公開 API 的使用狀況。這是目前少數用真實的大規模部署數據來研究 agent 行為的文章,而不是純靠 benchmark。發佈後在 Hacker News、Latent Space、LinkedIn 等社群都引發了不少討論。以下是幾個我覺得重要的發現:
Agent 的自主工作時間正在拉長
在 Claude Code 中,最長的 agent 工作時間(99.9th percentile)從 2025 年 10 月的不到 25 分鐘成長到 2026 年 1 月的超過 45 分鐘,三個月內將近翻倍。
有趣的是,這個成長是平滑的,沒有因為新模型發佈而出現跳躍。這暗示自主時間的增加不純粹是模型能力提升,還包含了用戶逐漸信任、嘗試更有野心的任務、以及產品本身的改進。
不過中位數其實變化不大,大約維持在 45 秒左右。會拉長的是那些 power user 的極端使用場景。
老手放更多手,但介入得更精準
Claude Code 用戶的行為變化很有意思:
- 新手只有約 20% 的 session 開啟 auto-approve,老手(750+ sessions)超過 40%
- 但同時,老手的 interrupt(中斷介入)頻率反而比新手高 — 從 5% 增加到 9%
這看似矛盾,其實是監督策略的轉變: 新手逐步核准每個動作所以不太需要中斷;老手放手讓 agent 跑,但靠經驗判斷什麼時候該出手拉回來。
這很像帶新人: 一開始盯著每一步,後來放手讓他做,但你的雷達反而更敏銳,知道什麼時候該出手。
公開 API 也看到類似的模式: 簡單任務有 87% 有人類介入,複雜任務反而只有 67%。因為步驟太多了,逐步核准根本不實際。
Agent 自己會停下來問問題
這點我覺得蠻重要的: 在最複雜的任務中,Claude Code 主動停下來問「釐清問題」(clarification) 的頻率,是人類主動中斷它的兩倍以上。
Claude 停下來的常見原因:
- 提出不同方案讓使用者選擇(35%)
- 需要診斷資訊或測試結果(21%)
- 請求釐清模糊的需求(13%)
- 需要 credentials 或權限(12%)
人類中斷 Claude 的常見原因:
- 提供技術背景或修正(32%)
- Claude 太慢或做過頭了(17%)
- 已經得到足夠的幫助,自己繼續做(7%)
這代表「agent 自己知道什麼時候該停」是一個重要的安全特性,不能只靠外部的權限管控,模型本身對自己的不確定性要有校準。
風險與自主性的分佈
研究用 1-10 分量化了每個 tool call 的「風險」和「自主性」。結果是大部分動作都落在低風險區,80% 有某種安全機制,73% 有人類在循環中。
但邊界上有些有趣的案例:
- 高風險高自主: 有人拿 agent 做 API key 後門植入(雖然很可能是 red team 測試)
- 高自主低風險: 自動系統健康檢查、email 監控告警、自動交易
- 高風險低自主: 醫療病歷調取、消防應急回應
上方右上角(高風險 + 高自主)目前還很稀疏,但隨著 agent 進入更多產業,這塊會越來越熱鬧。
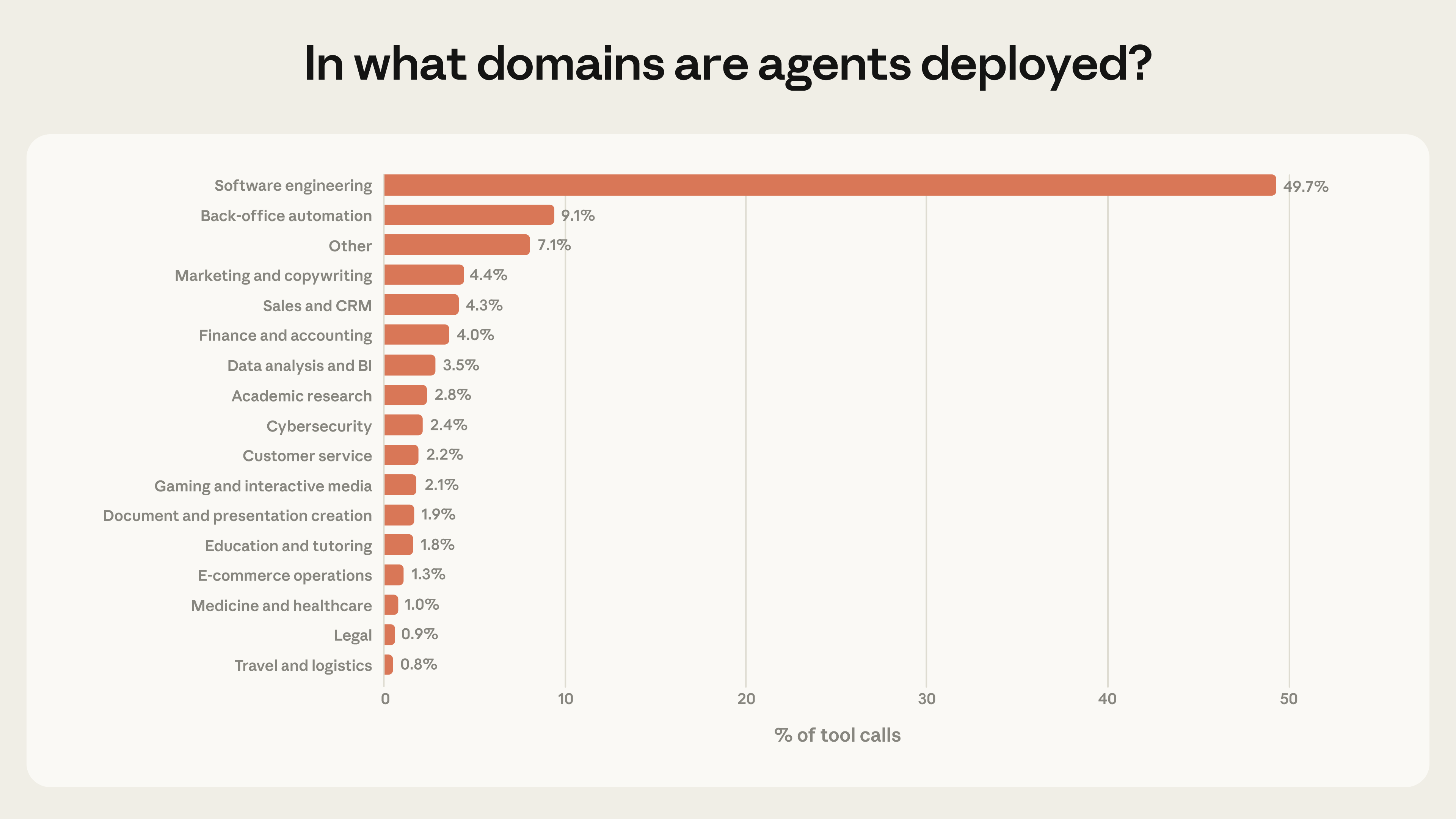
軟體工程佔了近 50%,然後呢?
回到我覺得最有啟發性的 Figure 6:
軟體工程佔了公開 API 上近 50% 的 agentic API 呼叫。
第二名是 Back-office automation 才 9.1%,後面的 Marketing、Customer service、Finance、Healthcare 全部加起來都不到軟體工程的一半。
為什麼軟體工程一枝獨秀?
- 工具鏈天然適合 Agent: 讀寫檔案、跑測試、執行 shell 命令、呼叫 API — 本來就是可以程式化操作的,不需要碰到物理世界
- 風險可控、動作可逆: 改錯了
git revert就好,不像發錯 email 或下錯交易單 - 開發者就是第一批使用者: 會建構 agent 系統的人自然先拿來解決自己的問題
其他產業的機會
但換個角度看,剩下的 50% 基本上還在起步:
🔹 醫療健康: 保險理賠文件處理、病歷摘要、診斷前資訊蒐集,市場巨大但風險等級高,需要更嚴格的 human-in-the-loop
🔹 金融與交易: 已經有人拿 agent 做自動加密貨幣交易(autonomy 分數 7.7),但合規和責任歸屬問題會限制大規模部署
🔹 客服與銷售: 加起來佔比不到 5%,但明明是 AI 最直覺的場景。可能很多企業還停留在簡單的 RAG pipeline 而非 agentic 架構
🔹 Back-office 自動化: 9.1% 排第二,跟 RPA 市場重疊,但 agent 比傳統 RPA 靈活太多,可以處理非結構化的情境
Deployment Overhang: 模型能力 > 實際部署
研究用了一個很棒的概念:「deployment overhang」— 模型的能力已經到了,但實際部署的自主程度遠遠落後。
METR 的評估顯示 Claude Opus 4.5 能處理人類要花近 5 小時才能完成的任務,但 Claude Code 的 99.9th percentile 自主工作時間才 45 分鐘,中位數更只有 45 秒。
這個落差對做產品的人來說就是機會: 不是模型不行,是產品層面的信任機制、監控工具、權限控制還沒做好。誰能在垂直領域把這些做好,誰就能釋放 agent 的潛力。
網路上的討論與批評
這篇研究發佈後引起了不少迴響,值得一起看:
Hacker News 上的質疑: 有人指出,用前 0.1% 極端值的工作時間來衡量自主性,有刻意挑選數據的嫌疑。也有人認為純粹量測時間長度意義不大 — 不同硬體上跑同樣的任務,時間差異巨大,如果不控制 token 生成速度和輸出品質,這個數字本身說明不了什麼。這些批評有道理,但我認為 Anthropic 的重點不在絕對數字,而是趨勢方向。
Latent Space 的整理: swyx 在 AINews 中點出幾個關鍵數字 — 約 73% 的工具呼叫仍有人類參與監督,只有 0.8% 是不可逆的操作,而軟體工程佔了 API 端約 50% 的 API 呼叫。他用「部署落差」(deployment overhang)這個概念來框架化這個現象,呼應了研究本身的核心觀點。
The Atlantic 工程團隊的延伸思考: Matt White 在 The Autonomous AI Trifecta 一文中,把 agent 設計拆成三個維度:自主性(Autonomy)、能力範圍(Power)、安全保證(Assurance),並指出「你不可能同時把三個都開到最大」。他認為現代 agent 的評估方式,應該更像網站可靠性工程(SRE)那樣去量測服務品質,而不是像考試打分數 — 因為一旦 agent 的輸出變成真實系統的輸入,你就繼承了整個社會技術系統的複雜度:權限、合規、監控、事件回應、稽核等等。這個觀點我覺得非常精準。
LinkedIn 上的實作者觀點: Guru Chahal 總結得很到位:有效的監督不是逐一批准每個動作,而是在關鍵時刻有能力介入。
這些討論反映出一個共識正在形成:agent 的挑戰已經從「能不能做」轉移到「怎麼安全地放手讓它做」。
小結
這篇研究的價值在於用真實數據畫出了 AI Agent 產業的現狀。軟體工程走在最前面,其他產業機會巨大但需要解決信任和風險控制。對 AI Engineer 來說,接下來的挑戰不只是讓 agent 更聰明,而是設計出讓人類能有效監督 agent 的產品機制 — 尤其是在那些出錯代價高昂的領域。
正如 The Atlantic 工程團隊所說,這是 Autonomy、Power、Assurance 三者之間的取捨。誰能在垂直領域找到最佳平衡點,誰就能釋放 agent 真正的潛力。