2025 年 LLM 發展回顧: 推理模型、Benchmaxxing 與未來預測
看到 Sebastian Raschka 寫了一篇超長的 The State Of LLMs 2025 年度回顧文,把 2025 年 LLM 領域的重大發展都梳理了一遍。Sebastian 是 LLM 技術圈很有影響力的作者,他的 Build A Large Language Model (From Scratch) 那本書被翻譯成九種語言,非常受歡迎。這篇文章資訊量很大,以下摘我覺得最有價值的幾個觀點:
DeepSeek R1 定義了 2025 年
今年 LLM 發展的關鍵詞就是「推理模型」,而開端就是一月份 DeepSeek R1 的發佈。它帶來三個衝擊:
- 開放權重的推理模型: R1 是 open-weight,性能媲美當時最好的閉源模型
- 訓練成本的重新估算: 大家回頭看 DeepSeek V3 的論文,發現訓練 SOTA 模型的成本可能是 500 萬美元等級,而不是之前以為的 5000 萬到 5 億。R1 在 V3 基礎上的 RL 訓練更只花了約 29 萬美元
- RLVR + GRPO 成為新範式: 用「可驗證的獎勵」(Reinforcement Learning with Verifiable Rewards) 搭配 GRPO 演算法來訓練推理能力,不再需要昂貴的人工標註偏好資料
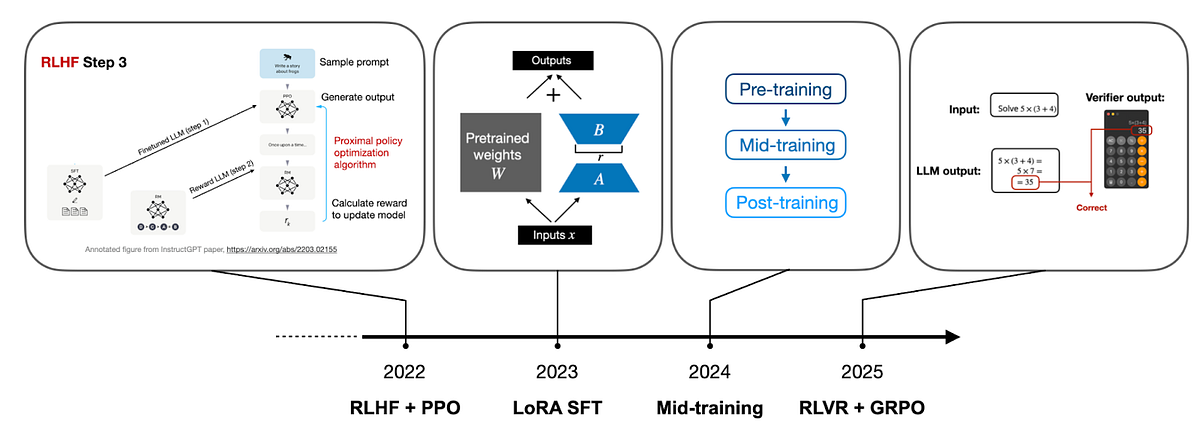
之後幾乎所有主要的 LLM 開發者都推出了自己的推理(thinking)模型版本。Sebastian 整理了每年 LLM 發展的主旋律:
- 2022: RLHF + PPO
- 2023: LoRA SFT
- 2024: Mid-Training
- 2025: RLVR + GRPO
不只靠 Scaling 了
GPT 4.5 是個很好的例子。據傳它比 GPT 4 大很多,但能力提升被認為是 “bad bang for the buck”。2025 年的進步更多來自:
- 更好的訓練流程: mid-training 和 post-training 的精進
- 推論時擴展(inference-time scaling): 花更多算力在生成答案的階段。DeepSeekMath-V2 就靠這個在數學競賽 benchmark 達到金牌水準
- 工具使用: 讓 LLM 學會用搜尋引擎、計算機等工具,大幅降低幻覺率。OpenAI 的 gpt-oss 就是以工具使用為核心設計的 open-weight 模型
Benchmaxxing 的問題
Sebastian 用 “benchmaxxing” 來形容今年的一個趨勢: 過度追求 benchmark 分數,甚至把跑分本身當成目標。最明顯的例子是 Llama 4,benchmark 分數亮眼,但實際使用體驗跟分數完全對不上。
他的觀點蠻務實的: benchmark 分數低於某個門檻,代表模型不行;但分數高不代表真的比另一個高分模型好。公開的 test set 早就不是真正的 test set 了。
開源生態的洗牌
幾個他覺得意外的事:
- Llama 失寵,Qwen 崛起: 按下載量和衍生模型數,Qwen 已經超越 Llama
- Mistral 直接用 DeepSeek V3 架構: Mistral 3 的底層就是 DeepSeek V3
- 更多玩家冒出來: Kimi、GLM、MiniMax、Yi 都在爭 open-weight SOTA
- MCP 成為標準: 比預期更快地統一了 agent 系統的工具和資料存取協議
LLM 是超能力,不是替代品
這段我覺得寫得最好。Sebastian 的核心觀點是: LLM 給人「超能力」,但不該完全取代人的思考。
他自己寫 LLM 訓練腳本時,核心邏輯還是自己寫、自己仔細看過,確保理解和正確性。但周邊的 boilerplate 程式碼就交給 LLM。他也用 LLM 處理非核心專長的事,像是備份 Substack 文章、清理 CSS 等。
更深層的觀點是: 如果人只負責監督而 LLM 做所有事,工作會開始感到空洞,長期可能加速 burnout。他用下棋做比喻——AI 早就超過人類棋手了,但人類的職業棋賽反而更豐富有趣,因為棋手用 AI 來探索新想法、挑戰直覺、分析錯誤。這才是對的用法。
一個有經驗的全端工程師用 LLM,做出來的東西還是會比一個隨便 prompt 的人好很多。厲害的是,現在隨便一個人也能做出東西了,但品質會到一個天花板——如果真的在乎,還是得深入學。
2026 預測
- RLVR 擴展到數學和程式以外的領域(化學、生物等)
- 更多 inference-time scaling 的進展
- 傳統 RAG 會逐漸退場,被更好的長上下文處理取代
- 進步更多來自推論端的改善,而非訓練端
- 消費級的 diffusion 語言模型可能出現(Gemini Diffusion)
以上,Sebastian 每年的回顧文都寫得非常紮實,這篇更是涵蓋了技術、生態、哲學層面。全文很長但值得讀完,推薦。
原文: The State Of LLMs 2025: Progress, Progress, and Predictions