RAG 不只是 Vector Search: 從語意相似度到真正的搜尋理解
看到 Doug Turnbull 這篇 RAG Isn’t a Vector Search Problem,覺得講到一個很多人踩過的坑。Doug 是搜尋領域的老手,寫過 Relevant Search 這本書,在 Elasticsearch/OpenSearch 圈子很有名,現在專注在 LLM + Search 的交集。
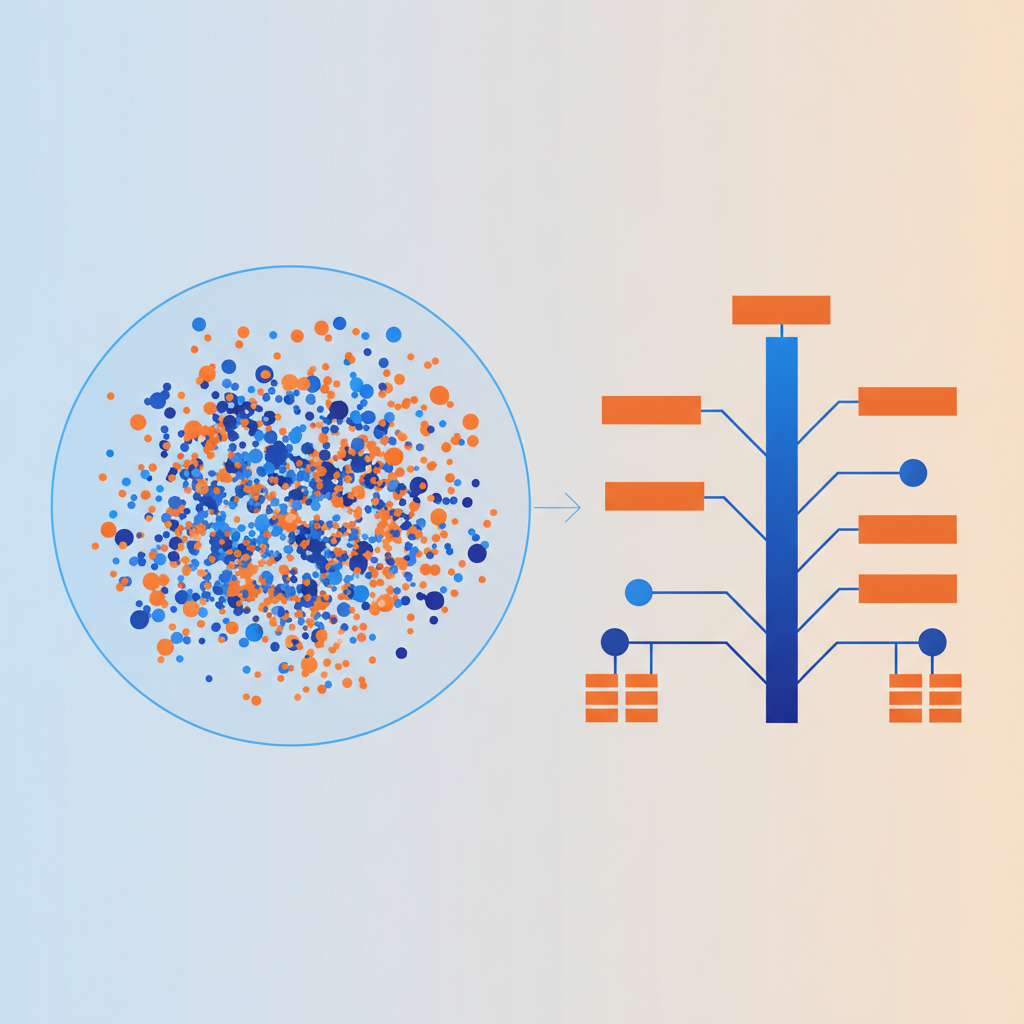
很多人做 RAG 的第一直覺是: 把文件切 chunk、跑 embedding、丟進 vector DB,然後用 cosine similarity 找最相近的段落餵給 LLM。這條路走到底會發現效果撞牆,而且很難改善。Doug 這篇講的就是為什麼會撞牆,以及真正該怎麼想這個問題。
Vector Search 的根本問題
Doug 指出幾個 embedding 檢索的痛點:
1️⃣ Embedding 擁擠 (Crowding): 通用 embedding 模型是在大規模網路資料上訓練的,但你的資料是特定領域。結果就是你的所有文件在向量空間裡擠成一團,cosine similarity 可能都在 0.8-0.9 之間,很難區分真正相關和不相關的內容。比如 S1 上市公告和季度財報,對通用模型來說都是「財務報告」,但對你的使用者來說是完全不同的東西。
2️⃣ 沒有 match/no-match 的概念: Vector search 只給你一個連續的相似度分數,沒有明確的「這個匹配/這個不匹配」的界線。你設 threshold 0.8 來過濾,結果同一個 threshold 在不同 query 上表現完全不一樣。搜「法國首都」的正確答案可能 0.9,但「列出法國所有城市」的正確答案可能只有 0.6。
3️⃣ 通用排名 ≠ 你的領域排名: 在 MTEB 排行榜上表現好的模型,不代表在你的金融、法律、醫療資料上也好用。領域特有的術語和概念,通用模型不一定能理解。像「high yield」在金融領域是指垃圾債券,不是「高收益」; 「Chinese wall」在銀行業是資訊隔離牆,不是中國的牆。
使用者要的是操作資料的能力
這裡 Doug 引用了 HCI 大師 Donald Norman 的「affordance」概念: 使用者想知道他們能對資料做什麼操作,怎麼選取、過濾、探索。
舉個例子,搜家具的人想用「風格 + 材質 + 房間類型」來篩選; 搜財報的人想用「公司代碼 + 報告類型 + 時間範圍」來篩選。這些都是結構化的選取條件,不是一個模糊的語意相似度能處理的。
使用者要的其實是:
SELECT * FROM your_data WHERE <stuff_that_matters_in_your_data>
而 LLM 的工作,是把自然語言翻譯成那些「對你的資料有意義的篩選條件」。
LLM 是 Query Understanding 的利器
這是整篇文章最核心的洞見: LLM 最大的價值不是拿來算 embedding,而是拿來做 query understanding。
使用者輸入自然語言:
給我看麂皮幾何圖案的沙發
LLM 把它翻譯成結構化查詢:
{
"styles": ["geometric"],
"materials": ["suede"],
"classification": "Living Room / Seating / Sofas"
}
每個欄位可能用完全不同的檢索策略:
- 風格 → 用 CLIP 之類的視覺 embedding
- 材質 → 用精確匹配 + taxonomy 相似度
- 分類 → 用階層式分類樹
這比把所有東西壓進一個 embedding 空間要精確太多了。而且每個維度的匹配邏輯都能解釋,使用者能理解為什麼搜到這些結果,也能有效地修正搜尋。
搜尋不只是相關性排序
Doug 也提醒,好的搜尋不只看 passage similarity,還要考慮:
- 熱門度: 這個東西現在是不是很熱門?
- 時效性: 文件是最近發佈的還是很舊的?
- 權威性: 資訊來源可不可信?
- 多樣性: 搜「餐廳工作」不應該顯示 10 個同一家連鎖店的職缺,而是要展示各種不同類型的餐廳工作
特別是多樣性這點,在 agentic RAG 裡更重要。Agent 需要看到多元的搜尋結果才能判斷要不要換個方向重新搜尋,如果結果都長一樣,Agent 根本學不到什麼。
Vector Search 的正確位置
Doug 不是在說 vector search 沒用。他的觀點是: vector search 應該是 fallback,不是第一選擇。
好的搜尋架構應該是:
- 先用 LLM 做 query understanding,把使用者意圖拆解成結構化條件
- 用結構化查詢精確檢索(分類、過濾、精確匹配)
- 對於無法結構化的部分,才用 embedding 做模糊排序
- 最後綜合所有信號排序
這跟 Google 的做法其實一樣: 如果 Google 知道你在搜電影,它會給你結構化的場次、評分資訊; 只有在完全不確定你要什麼的時候,才 fallback 到傳統的文字排序。
我的想法
這篇文章其實點出了很多 RAG 專案失敗的根本原因: 大家把太多注意力放在「用什麼 embedding 模型」「怎麼切 chunk」「要不要 rerank」,卻沒有花時間去理解自己的資料結構和使用者到底想怎麼操作資料。
RAG 不是一個 ML 問題,更像是一個資訊架構 (information architecture) + 資料建模的問題,只是現在我們有了 LLM 這個超強的 query understanding 工具,可以把以前需要花好幾個月建規則系統的事情,在幾天內搞定。
推薦搭配他另一篇 Semantic Search Without Embeddings 一起看,講的是用 taxonomy + LLM 取代 embedding 做語意搜尋,思路很一致。