讓 AI Agent 更可靠的 9 種方法: 從 Workflow Builder 到 Response Caching
看到這篇 Butter 團隊的 Erik Dunteman 寫的 The Messy World of “Deterministic Agents”,把目前業界試圖解決 agent 不確定性問題的各種方法整理得蠻清楚的。
用過 Cursor 或 Claude Code 的人應該都有這個經驗: 同樣的任務,agent 第一次做對了,換個輸入再做一次,它就走了一條完全不同的路。這種不可預測感讓人很難信任 agent。我們想把 agent 當成可以委派任務的員工,但員工會學技能、會越做越熟,agent 不會。
文章定義的核心目標是「確定性重播」: 給同樣的任務,agent 能穩定地產生一致的 tool call 軌跡。以下是 9 種不同的嘗試:
1. Workflow Builders
像 Zapier 那樣的拖拉式畫布工具,把預建的整合串在一起,中間穿插 LLM 做資料轉換和分類路由。嚴格來說這不算 agent(控制流不是 LLM 決定的),但企業用戶喜歡它的可解釋性和真正的確定性。代表產品是 n8n,OpenAI 最近推的 Agent Builder 也是這個路線,雖然很多人對它掛「agent」的名字有意見。
文章引用了 Simon Willison 對 agent 的定義: An LLM agent runs tools in a loop to achieve a goal. 後面 8 種方法都是在這個架構下,探索如何讓 LLM 的分支決策變得更可預測。
2. Context Engineering
把問題看成「上下文」問題 — agent 缺乏過去成功執行的知識,那就把成功的 run 塞進 context 裡。這可以追溯到 few-shot prompting 和 RAG,代表產品如 mem0 和 Supermemory。
注入的內容可以包括: 使用者偏好、SOP 文件、過去的 agent 軌跡紀錄、軌跡的 LLM 摘要、推理追蹤等。不能強制確定性,但可以引導模型。
3. Explicit Skills
事先建好知識庫,像員工 onboarding 文件一樣,讓 agent 在執行時選擇性參考。Anthropic 最近推出的 Claude Skills 就是這個路線 — 本質上是對 SOP 和文件做 RAG。需要預先知道 agent 會執行哪些類型的任務。
4. Learned Skills
跟 Explicit Skills 相反,技能是從歷史訊息中事後歸納出來的。Cursor 的 Memory 功能就是這樣 — 有個特殊的「save to memory」tool,偵測到有用的行為就存下來供未來使用。Letta 的 Sleep-Time Agents 也很有創意,用非同步 agent 持續把歷史訊息壓縮成更精煉的摘要。
5. Code Generation
既然目標是穩定重現 tool call,最確定性的工具就是程式碼本身。與其讓 LLM 每一步都做選擇,不如把 LLM 當成編譯器,預先產生程式碼去直接呼叫 tool function。Cloudflare 的 Code Mode 和 Browser Use 的 Code Use 都是這個思路。腳本是一次性的,但「用程式碼呼叫工具」的概念是下一個方法的基石。
6. Meta-Tools
有時候產生出來的程式碼值得存成一個新的 tool。讓模型不只是使用工具,還能建立自己的抽象層,每次 tool call 決策都更有力。這跟「agent 是 tool loop」的架構完美契合 — 模型繼續選工具,只是那些工具現在能執行越來越長(且確定性的)任務。
先驅是 2023 年的 Voyager 論文,在 Minecraft 裡用即時 tool 生成把原始 API 進化成更高階的抽象。超前時代,但到現在還沒有真正的後續產品。
7. Script-Agent Fallback
預設走純軟體執行,agent loop 只用在初始探索和自我修復。通常是讓 agent 或人類先執行幾次工作流,從 tool call trace 產生可重用腳本。在瀏覽器自動化領域特別流行,代表有 Browserbase 的 Director 和 Browser Use 的 Workflow Use。
跟 workflow builder 類似,需要事先知道要跑什麼任務,但分支行為不需要預先定義。
8. Script Generators
「自動化版的 Lovable」— 技術或非技術用戶跟 codegen agent 互動,產生純軟體腳本,runtime 完全不需要 agent。有些團隊甚至設計 DSL 來表達自動化邏輯,用自定義 grammar 強制生成,減少錯誤和幻覺的表面積。代表團隊有 Forge 和 Sola。
9. Response Caching
在 LLM provider 前面放一個 HTTP proxy,快取 response。重複請求時直接從 cache 回覆,agent loop 完全不知道自己被引導到確定性路徑上。這是 Butter 自己在做的方向。
要達到有意義的 cache 命中率,需要解決語義相似 prompt 的分群、動態資料辨識、noisy context 過濾、複雜條件控制流等問題,挑戰不小。
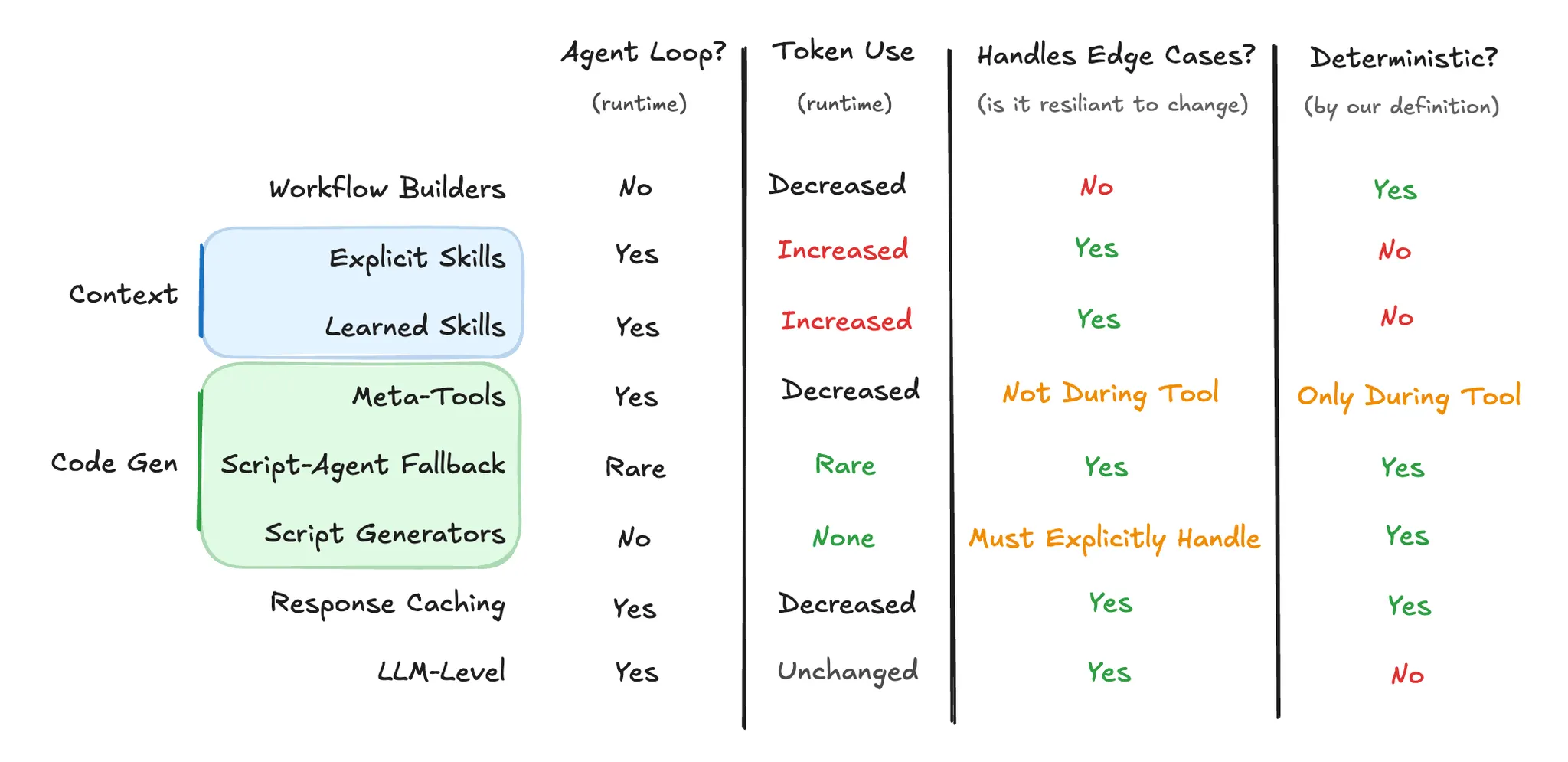
總結比較
原文最後有一張表,整理了各方法在幾個關鍵面向的表現:
文章最後也提到兩個 LLM 層級的改進方向: Action Models(decoder 直接輸出 tool call 而非 token,常用於機器人領域,General Agents 的 Ace 是電腦自動化的例子)和 RL(很多自動化任務有快速的成功/失敗回饋,適合做 reward function)。
我覺得這篇最有價值的地方是把這些方法按抽象層級排列,從最高層的 workflow builder 到最底層的模型改進,讓人可以清楚看到各種 tradeoff: 越高層越確定但越不靈活,越底層越通用但越不成熟。
現實中大概不會只用一種,而是根據任務特性混搭。對確定性要求高的用 workflow builder 或 script generator,探索性強的用 context engineering 加 learned skills。重點是理解每種方法的適用場景,而不是押寶某一種。