AI Evals 閃卡全解析: Hamel Husain 的 12 張 Evals 精華卡片

看到 Hamel Husain 做了一套 Evals Flashcards,一共 12 張卡片,把 AI Evals 的核心觀念濃縮成圖解。Hamel 是 LLM 應用圈很活躍的實踐者,之前在 GitHub 做 Copilot 相關的工作,現在專注顧問和教學,他的 evals 觀點一直很務實,強調「先看數據再寫 eval」這個基本功。
這套卡片是他 AI Evals 課程 的教材,每張都精煉到一個核心概念。以下逐張解說:
卡片 1: 如何做 Error Analysis

這是整套方法論的起點。Error Analysis 的目的是從你的 AI 產品 logs (traces) 裡快速找到失敗模式。
流程是一個循環:
- 收集 Traces: 從 production 或自己的使用中蒐集 100+ 條多樣化的 traces
- 標註 (Open Coding): 逐條看,寫簡短筆記描述問題(例如「hallucinated a fact」、「failed to use calculator tool」)
- 分群歸類: 把類似的筆記聚成 cluster(例如: tone violation、failed tool call)
- 排優先級: 計算每個類別的頻率,決定處理順序
關鍵概念是「理論飽和」(theoretical saturation): 一直看數據直到你覺得沒有新發現為止。經驗法則是大約需要 100 條高品質、多樣化的 traces。
卡片 2: 什麼時候該寫 Eval
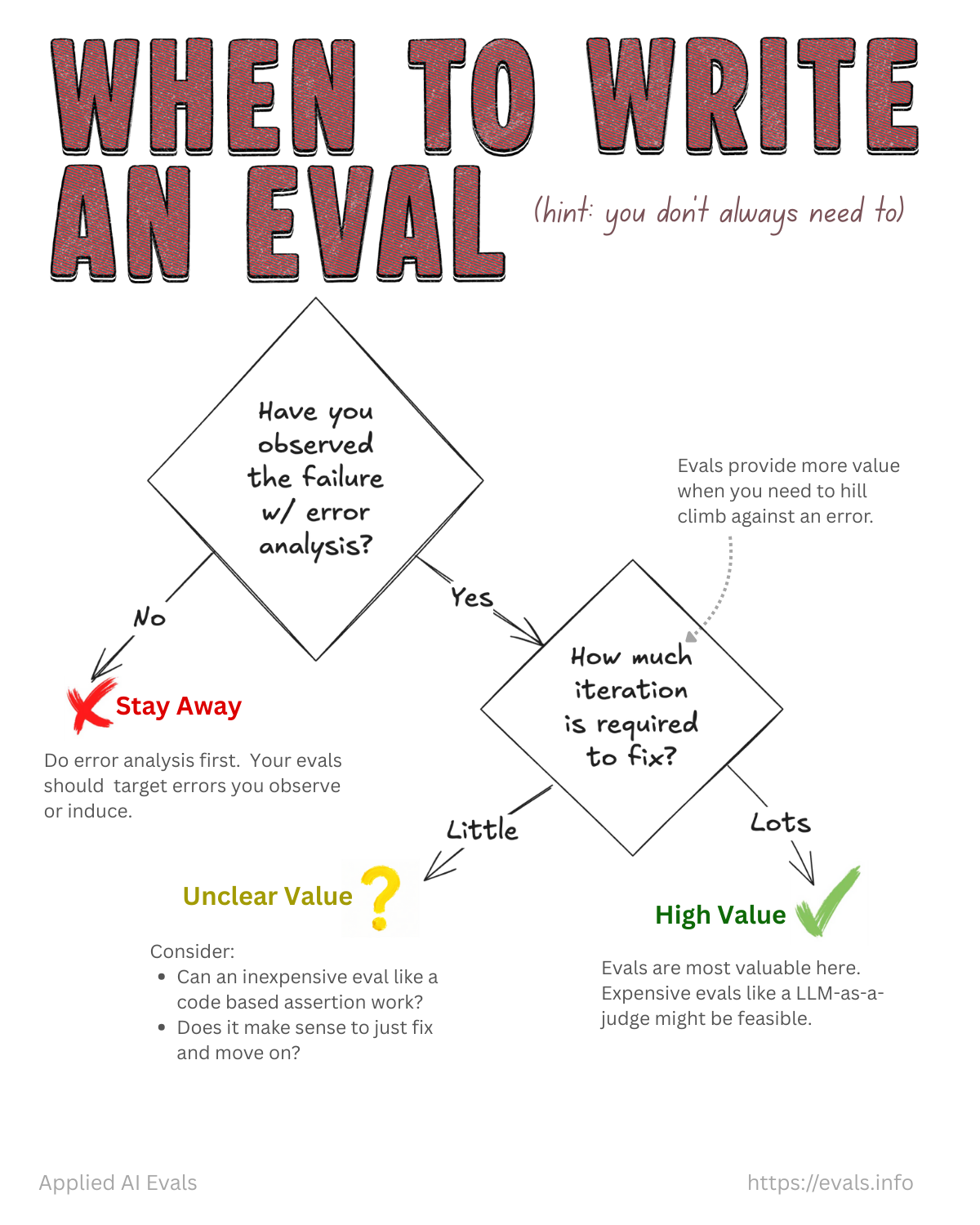
不是每個問題都需要寫 eval。這張卡片給了一個決策流程:
- 你有透過 error analysis 觀察到這個失敗嗎? 沒有的話,先回去做 error analysis。你的 eval 應該針對你觀察到或誘發出的錯誤。
- 修復需要多少迭代? 如果修復很快,eval 的價值不大——考慮用簡單的 code assertion 或直接修好就好。如果需要大量迭代來 hill climb,那 eval 的價值就很高,這時候像 LLM-as-a-judge 這種比較貴的 eval 就值得投入。
核心觀點: eval 的價值在於幫你迭代改進,不是為了寫而寫。
卡片 3: 不要用通用的 Eval Metrics

這張直接打臉很多人的做法。
❌ 不要用的: Rouge、BLEU、Faithfulness、Helpfulness、Tone 這些通用分數
✅ 應該用的: 針對你的應用的具體指標,例如「日曆排程失敗」、「對話流程中斷」、「Widget 渲染錯誤」、「Email 收件人錯誤」、「未能轉接給人類客服」
好的 eval metric 要符合以下 checklist:
- 衡量你觀察到的錯誤
- 關聯到一個需要迭代的非瑣碎問題
- 範圍限定在特定失敗
- 結果是 binary(不是 1-5 分)
- 可以驗證(有 human labels 來對比 LLM Judge)
卡片 4: 常見的 AI Eval 錯誤

三個最常犯的錯:
-
不看數據就跳去做自動化 eval: 如果你不知道你的具體失敗模式,自動化 eval 就是白做。現成的「Helpfulness score」之類的指標就是壞在這裡。
-
用 LLM Judge 但沒對 human label 做驗證: 不比對人類標註,你的 judge 就是不可信且沒校準的 metric。
-
所有 eval 都滿分就覺得很開心: eval 最大的價值是找到新的失敗。全部 100% pass 通常代表你的 eval 已經飽和或太簡單了,應該加入更難的 test case。
卡片 5: 自動化 Eval 的三種類型

-
Code-based assertions: 檢查客觀的、基於規則的失敗,例如 keyword matching、確認 tool 有被執行等。能用就盡量用,因為快、便宜、確定性高、可解釋。
-
LLM-as-a-judge: 用 LLM 來評估主觀或有 nuance 的標準,code 搞不定的才用。比較慢、貴,而且需要驗證和校準。只用在重要的失敗上。
-
Guardrails: 在 request/response 路徑上即時攔截失敗,在到達用戶之前就擋下。通常是 code-based check 或小型 classifier,要求速度快、false positive 率低。
卡片 6: 不要用 Likert Scale (1-5 分)

這張很重要。用 LLM-as-a-judge 時,binary (pass/fail) 幾乎總是比 1-5 分好。
為什麼 Likert scale 有問題:
- 要跟 domain expert 校準成本很高
- 標註者傾向選中間值來逃避困難判斷
- 容易鼓勵太大的 scope(變成一個「整體品質分數」而不是針對性的 eval)
Binary 的好處:
- 迫使標註者做明確決定
- 更符合現實——你最終得決定 AI 功能到底夠不夠好可以 ship
- 在 error analysis 時更容易套用
卡片 7: 如何信任 LLM Judge

信任 LLM Judge 的唯一方式是對 human labels 做衡量。
做法: 把人類標註的數據分成三份:
- Train (~20%): 從這裡抽 few-shot examples 放進 judge prompt
- Dev (~40%): 用來優化你的 judge
- Test (~40%): 最終驗證,確保沒有 overfit
注意比例跟傳統 ML 不同,因為你不是在「訓練」什麼,只是用數據來指導 judge prompt。
評估指標: 不要報 accuracy(在 imbalanced data 上會誤導)。用 True Positive Rate (TPR) 和 True Negative Rate (TNR),目標是兩者都 > 90%。
卡片 8: Trace 的採樣方式
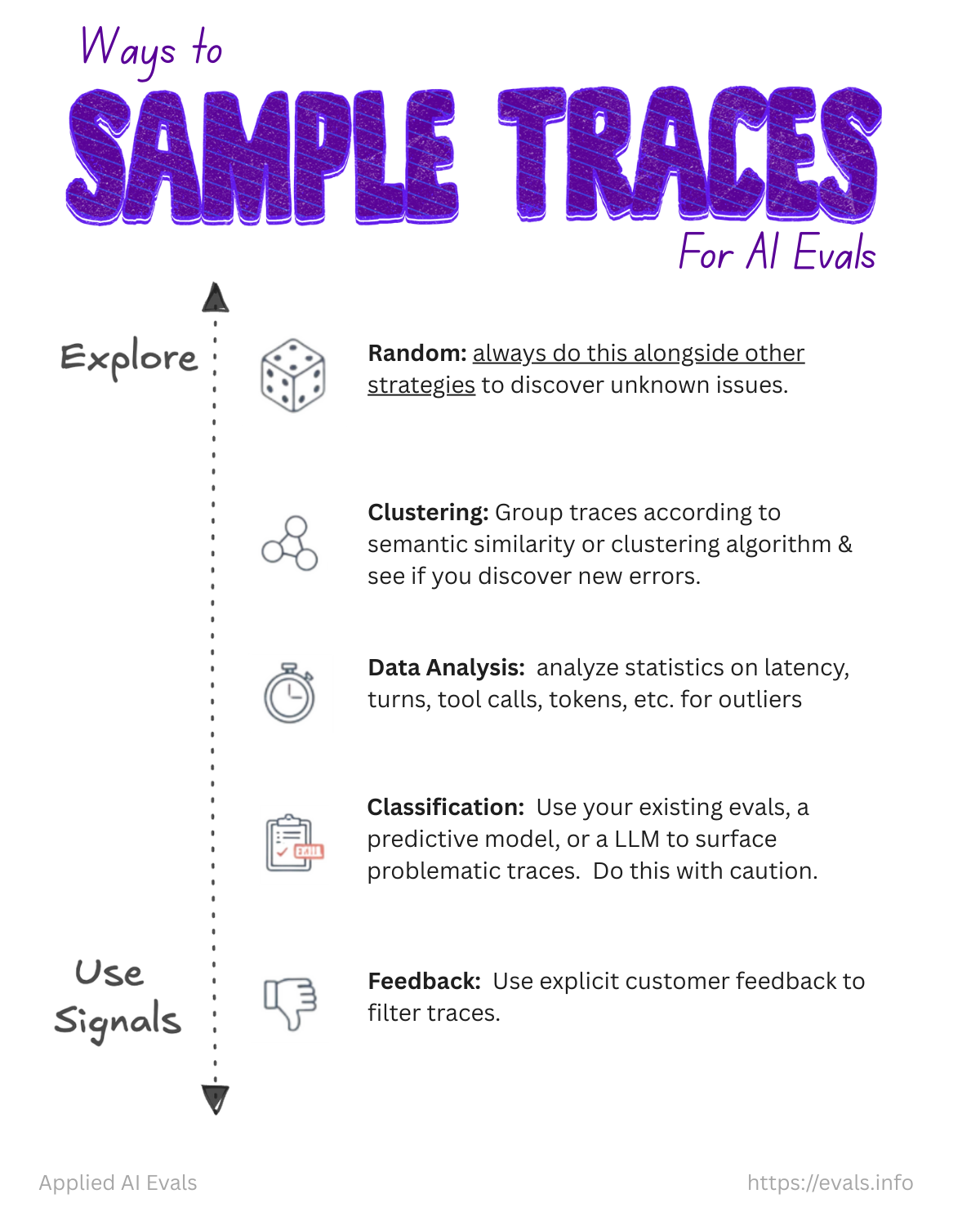
怎麼從大量 traces 裡選出有代表性的樣本來做 eval:
探索性方法:
- 🎲 隨機抽樣: 永遠搭配其他策略一起用,用來發現未知問題
- 🔗 Clustering: 按語意相似度分群,看能不能發現新的錯誤類型
- ⏱ 數據分析: 看 latency、turns、tool calls、tokens 等統計的 outliers
- 📋 分類: 用現有 eval、預測模型或 LLM 來找出問題 traces(謹慎使用)
利用訊號:
- 👎 用戶反饋: 用明確的客戶回饋來過濾 traces
卡片 9: 合成數據生成技巧

用 synthetic data 來 bootstrap evals 的實用建議:
- 用結構化輸入來確保多樣性: 定義關鍵維度(Feature、Persona、Scenario),作為 prompt 的變數
- 盡量用真實 log 做種子: 讓模型在真實數據基礎上注入變化,創造 realistic edge cases
- 強制輸出結構 + 過濾: 定義 output schema,大量生成後只保留最高品質、最有挑戰性的
- 逐步增加複雜度: 從簡單 query 開始,逐步加入 constraints 和複雜格式
❌ 不要做的: 零 context 的 prompt 像「Generate 50 test cases」,這種出來的東西又 generic 又重複。
卡片 10: 如何用 Trace 來做 Eval

從 trace 到 eval 的具體步驟:
- 做 error analysis 時,停在你發現的第一個(最上游的)錯誤。上游的失敗通常更重要。
- 蒐集跟你 top failures 相關的 traces,用最少的 turns 和最低的複雜度來最小化重現失敗。
- N-1 方法: 用錯誤發生前的 N-1 個 turns 作為 test case(假設你的系統沒有快速變動)。
- 進階: 用 LLM 對步驟 3 的 traces 做合理的修改(改寫 user question 等)來增加 test coverage。
- 進階: 用另一個 LLM 來模擬用戶,但做好不容易。
卡片 11: Transition Matrix 找錯誤熱點

這張是給多步驟 agent 用的。當 agent 有很多 state(Plan → Search → Code → Finalize),很難知道哪個步驟最常失敗。
Transition Failure Matrix 的做法:
- 列出 agent 所有可能的 state
- 建一個矩陣,row 是「從哪個 state」,column 是「到哪個 state」
- 對每個失敗,找出錯誤前最後一次成功的 transition,在對應的格子裡計數
這樣就能一眼看出失敗熱點。例如 GenSQL → ExecSQL 的失敗數是 12,那你就知道 SQL 執行是最大的痛點。非常實用的偵錯方法。
卡片 12: 如何部署 Eval
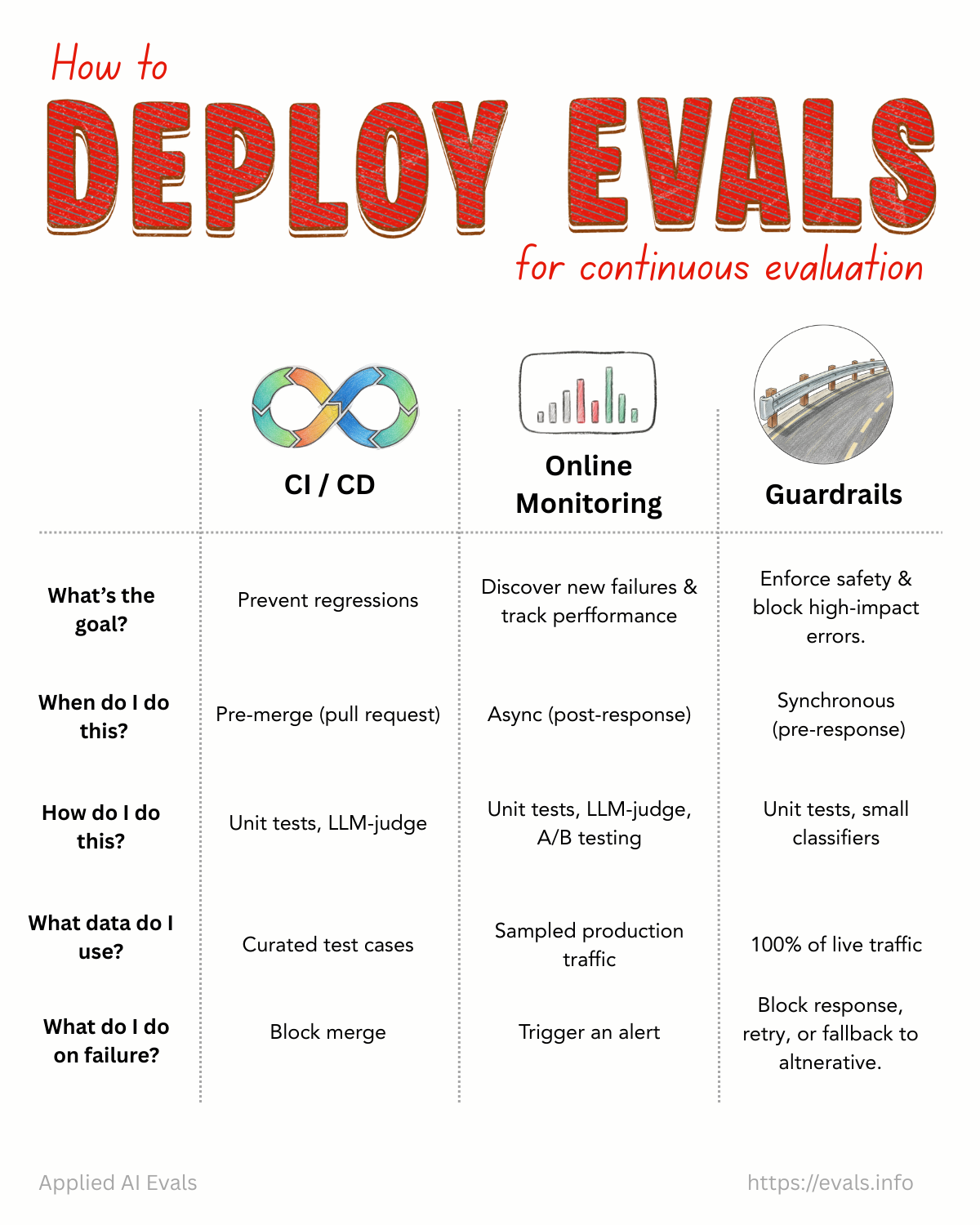
最後一張把 eval 的部署分成三個場景:
| CI/CD | Online Monitoring | Guardrails | |
|---|---|---|---|
| 目標 | 防止 regression | 發現新失敗、追蹤效能 | 強制安全、擋住高影響錯誤 |
| 時機 | Pre-merge (PR) | 非同步 (post-response) | 同步 (pre-response) |
| 方法 | Unit tests, LLM-judge | Unit tests, LLM-judge, A/B testing | Unit tests, 小型 classifiers |
| 數據 | 策劃好的 test cases | 抽樣的 production traffic | 100% live traffic |
| 失敗怎辦 | Block merge | 觸發 alert | Block response, retry, 或 fallback |
這 12 張卡片整個串起來其實就是一套完整的 AI Evals 方法論: 從 error analysis 開始(卡片 1),判斷什麼需要 eval(卡片 2),選對 metric(卡片 3-4),選對工具(卡片 5-7),蒐集好數據(卡片 8-10),診斷 agent 失敗(卡片 11),最後部署到 production(卡片 12)。
我覺得這套東西最值得帶走的觀念是: 先看數據,再寫 eval。太多人跳過 error analysis 直接套 generic metrics,結果 eval 分數好看但產品問題依舊。Hamel 反覆強調的「觀察具體失敗 → 針對性衡量 → binary 判斷 → 對 human label 驗證」這個循環,才是讓 eval 真正有 ROI 的關鍵。